What is AI?
- 11 minsWhat is AI?
알고 얘기하자
최근, 뉴스나 SNS 등 다양한 매체를 통해 우리는 ‘AI’라는 단어에 익숙해져 있다. 그런데 정작 초등학교를 다니는 사촌동생이 AI가 뭐야?라고 묻는다면 명쾌하게 대답해줄수 있는 사람이 과연 몇이나 있을까?
이런 사람들을 위해, AI를 처음 접하는 이부터 전공자까지 AI부터 데이터 사이언스의 전반적인 이해를 도울 수 있는 글을 작성할 것입니다.
첫 포스팅인 만큼 AI, 머신러닝, 딥러닝, 데이터 사이언스에 대한 전반적인 설명을 하겠습니다.
이번 포스팅은 아래와 같은 순서로 진행합니다.
- What is AI?
- AI의 역사
- What is Machine learning?
- What is Deep learning?
- 정리
- reference
1. What is AI?
Artificial Intelligence(AI)는 위키피디아에 검색을 하게 되면 “인간과 같은 동물이 보여주는 지능이 아닌 기계가 보여주는 지능”이라고 나옵니다. 다시말해 생체신호를 이용하여 어떤 사고를 통해 행동을 하는 것이 아니라, 디지털 신호들을 조합하여 어떠한 행동 혹은 결과를 기계를 통해 보여주는 기술이라고 생각하면 좋을 것같습니다.
AI는 크게 general AI, narrow AI로 나뉩니다. Generall AI란, 영화나 각종 애니메이션에 등장하는 생각하고 말하는 로봇이라고 생각하면 좋습니다. 간단하게 ‘인간수준의 사고를 지닌 AI’라고 할 수 있습니다. 영화 <아이언맨>의 '자비스', <엑스마키나>의 '에이바', <스타워즈>의 'C-3PO'<에이리언:커버넌트>의 데이빗 등등을 예로 들수 있습니다. Narrow AI란, 한가지 업무에 특화된 AI라고 생각하면 좋습니다. 예로 들면, 사진을 보고 어떤 동물인지 맞추거나, 소리를 듣고 어떤 소리인지 맞추는 작업 등 하나의 업무만 잘하는 AI를 보통 narrow AI라고 하며 메스컴에서 다루는 대부분의 AI기술은 narrow AI입니다. 최종적으로 이런 우수한 성능의 narrow AI들이 모이면 general AI를 구현할 수 있습니다.



2. AI의 역사?
그렇다면 이런 AI의 개념은 언제 처음으로 등장했을까요? 1950년 앨런 튜링이 튜링 테스트를 제안한게 AI의 상징적인 시작이라고 볼수 있습니다. 영화 <이미테이션 게임="">에서 베네딕트 컴버비치가 연기한 엘런 튜링이 그 주인공입니다.

튜링 테스트란???
인간평가자가 질의응답을 통해 컴퓨터와 인간을 구분하면서 최후에 판별을 통해 인공지능의 성능을 평가하는 테스트입니다. 여기서 핵심은 컴퓨터는 질문이 들어왔을때 인간과 동일하거나 유사한 대답을 하도록 개발이 되고 최후에는 인간평가자가 컴퓨터와 인간을 구분하지 못하는 것입니다. 최근 챗봇이나 고객상담 응대 AI 등 많은 질의응답기반의 AI들이 튜링 테스트를 통해 성능을 입증하고 있습니다.
그러나 1956년 John Macarthy가 주도한 다트머스 회의를 인공지능의 본격적인 시작이라고 생각하는 것이 일반적이며 그 회의에서 AI라는 단어가 처음 제안 되었습니다. AI는 총 3번의 황금기 2번의 침체기가 존재합니다.
첫번째 황금기 (다트머스 회의 ~ 74): 인공지능은 간단한 대수학을 풀거나 수학정리를 증명 했으며 이를 통해 사람들은 곧 인간의 지능을 뛰어넘는 인공지능 기계가 나올꺼라 생각했습니다.
첫번째 암흑기 (74 ~ 80) : 그러나 이런 인공지능은 한계가 존재하였고 ‘인간에겐 쉬운 것이 AI에게는 어렵다.’라는 모라벡의 역설과 ‘인간에겐 상식수준의 지식들도 AI는 모두 배워야 가능하다.’ 상식의 저주를 통해 AI는 한계가 있다라는 인식이 강해지면서 AI에 대한 투자가 위축되면서 암흑기에 들어섰습니다. 예를 들면 보거나 걷거나 어떤 물체를 휘두르는 행동이 인간에게는 배우지 않아도 자연스럽게 되지만 기계에게는 힘든 것이며 (모라벡의 역설) ‘인간에게는 눈과 귀가 있다’와 같이 배우지 않아도 자연스럽게 알 수 있는 상식도 기계는 학습을 해야만이 생각이 가능하다(상식의 저주). 라고 생각하면 이해가 쉬울 것입니다. 최종적으로 인간은 힘들이지 않고 해결이 가능한 간단한 문제들조차 기계는 해결이 힘들며 다양한 문제들이 뒤섞인 현실세계에서는 기계가 도저히 풀수 없다고 많은 대중들이 판단했으며 이에 암흑기가 시작되었습니다.
두번째 황금기 (80 ~ 97). : 첫번째 암흑기의 문제점을 분석하여 기계에 지식(데이터)를 넣으면 똑똑해질 것이라는 가정으로 시작되었습다. 한번에 모든 것을 완벽하게 처리할 수 있는 인공지능이 아니라 하나의 업무를 완벽하게 처리할 수 있는 인공지능을 만들어보자라는 컨셉으로 많은 기술들이 개발되었지만 ‘학습한 데이터 이외에는 잼병’이라는 치명적인 단점으로 인해 다시 암흑기로 접어들게 됩니다.
두번째 암흑기 (97 ~ ) : 인간은 비슷한 상황을 여러번 겪게 되면 ‘직관’을 통해 빠르게 문제해결이 가능하지만, 학습된 기계의 경우에는 다양한 변수들과 결과를 고려하여 행동하기 때문에 판단속도가 현저히 느리게 됩니다. 다시 앞의 모라벡의 역설, 상식의 저주에 맞닿게 됩니다.
세번째 황금기 (93 ~ ) : 현재 많은 연구와 투자가 진행되고 있는 machine learning과 deep learning이 이에 해당됩니다. 두번째 황금기에서 말했던 학습 데이터를 행동 데이터으로 저장하는 방식이 아니라 학습된 데이터를 통해서 새로운 데이터를 뽑아내자라는 컨셉에서 출발합니다. 두번째 황금기는 지식 데이터를 그냥 지식 데이터로 기계에 남겨 놓지만 ML & DL의 경우에는 ‘지식 데이터를 학습데이터로 사용하여 기계를 학습하자’라는 방식입니다.
이런 방식은 21세기에 인터넷의 발달로 인해 세계 곳곳의 수많은 데이터들을 사용할 수 있게되면서 더욱더 탄력을 받게 됩니다. 2세대는 문법을 기반으로 ‘i am a boy’를 ‘나는 소년입니다.’로 번역한다면 3세대는 다양한 데이터들에서 ‘i am a boy’가 어떻게 번역되는지 확률을 기반으로 번역을 하게 됩니다. 그리고 여기서 나아가 인간이 생각하는 방식에서 컨셉을 얻어 각 뉴런들이 어떻게 데이터를 전달하고 사용하는지를 모방하여 deep learning이 등장하게 됩니다.
예를 들어 우리가 고양이를 구분할 수 있는 이유는 과거에 몇번 고양이를 보고 우리의 뇌에 내장되어있는 tool이 작용하여 구분하는 것이지만 실상 우리는 뇌에서 어떤 현상이 일어나는지 알수 없습니다. 그러나 기계학습시에 이러한 고양이의 특징들을 가르치려든다면 장애가 있는 고양이나 개와 유사하게 생긴 고양이가 있다면 구분할 수 없고 이는 큰 오류로 작용할 수 있습니다. 그래서 deep learning을 통해서 수 많은 고양이 사진을 기계에게 학습시켜 기계가 스스로 자신만의 고양이 특징들을 배우게 하는 것입니다.
그러나 이런 방식에도 문제가 있습니다. 엄청나게 많은 양의 데이터를 학습시키기위해서는 데이터를 저장할 수 있는 공간이 매우 커야하며 이런 데이터들을 빠르게 학습시키기 위해서는 높은 연산속도의 컴퓨터가 존재해야했습니다. 그래서 과거에는 기술은 있었지만 물리적 한계로 인해 기술이 빛을 보지 못하였습니다. 그러나 2010년 GPU와 빅데이터에 대한 발전으로 빛을 보게 됩니다. 많은 한국사람들은 알파고로 인해 2016년이 딥러닝이 빛을 본 순간이라고 생각하겠지만 실제 2012 ImageNet에서 제프리 힌튼교수가 주도한 토론토대학의 SuperVision이 압도적 우승을 거둔 사전이 딥러닝의 가장 중요한 사건입니다. 이후, 14년 구글, 15년 마이크로소프트에서 기술을 개발하면서 인간보다 높은 성능을 지닌 딥러닝 기술들이 개발되기시작했고 현재까지 이미지뿐만 아니라 다양한 분야에서 딥러닝을 활용한 기술들이 개발되고 있습니다.
이제 AI, machine learning, deep learning이 구분가시나요? 우수한 AI를 개발하기 위해 narrow AI측면에서 기계를 사용하여 개발하려 시도를 했고 이것이 machine learning, macnine learning중에서도 데이터를 쌓는 것이 아니라 ‘데이터를 통해 인간과 유사한 방식으로 기계를 스스로 학습시키겠다’라는 것이 deep learning이라도 볼수 있습니다.
참고 : 딥러닝 개발자들은 알아두면 좋고 강의를 들어보시면 더 좋습니다.
Deep learning의 대가 : 제프리 힌튼, 요수아 벤지오, 얀 르쿤, 앤드류 응
youtube(제프리 힌튼 강의), youtube(얀 르쿤 강의), youtube(앤드류 응 강의)
3. What is Machine learning?
머신러닝이란 이름 그대로 기계를 학습시킨다는 개념입니다. 기계(컴퓨터)가 다양한 데이터들을 통해서 규칙을 찾도록 학습하는 것으로, narrow AI를 개발하기 위한 중간 단계에서 개발된 기술이며 2번째 황금기의 주된 컨셉입니다. 매스컴이나 많은 전문가들이 딥러닝 기술을 얘기할때, 머신러닝이라는 단어를 사용하는 이유가 바로 딥러닝 기술은 머신러닝에 기반하여 개발되었기 때문입니다. 그리고 딥러닝뿐만 아니라 우리가 일상생활에서 사용하는 대부분의 기술들이 머신러닝을 기반으로 개발된 기술들입니다. 예를 들면 검색창에 ‘머신’만 타이핑을 해도 ‘머신러닝’이라는 키워드가 완성되는 기술, 네비게이션 사용시 막히지 않는 길을 찾는 기술, 음원사이트에서 지금 듣고 있는 곡과 유사한 곡을 추천해주는 기술 등 우리가 인터넷을 통해 사용하는 대부분의 기술들이 머신러닝에 기반했다고해도 과언이 아닐정도로 머신러닝은 우리의 일상생활과 뗄레야 뗄수 없는 기술입니다.
그래서 학습을 어떻게 하는데?
머신러닝은 지도학습(superviesed learning), 비지도학습(un-supervised learning), 강화학습(reinforcement learning) 이렇게 3가지 방법이 있습니다.
지도학습(supervised learning)
먼저 지도학습은 학습시에 학습데이터와 정답데이터를 같이 주고 학습시키는 방법입니다. 예를 들어 지금 나오고 있는 음악이 어떤음악인지 알아맞추는 머신러닝 모델을 개발하고 싶다면, 학습데이터로 마이클잭슨의 bille jean을 사용하고 정답데이터로 michael jackson을 함께 넣어주는 겁니다. 그러면 최소한 이 모델은 어떤 음악이 들어와도 마이클 잭슨의 노래는 잘 알아맞출 수 있는 능력이 생기죠. 이렇게 학습하는 방법이 지도학습입니다. 주로 수치를 예측하는 task, yes or no등 이진분류에 대한 task를 수행할 시 혹은 다중 선택지에서 하나로 분류할 때 많이 사용되는 기법입니다.
비지도학습(un-supervised learning)
비지도학습은 지도학습과 달리 정답을 주지 않고 학습데이터로만 모델을 학습하는 기법입니다. 그러면 이 모델은 무엇을 배울까요? 바로 학습데이터들 속에서 비슷한 데이터들끼리 나눌 수 있는 능력이 생깁니다. 예를 들어 지금 나오고 있는 음악과 유사한 음악을 추천하는 머신러닝 모델을 개발하고 싶다면, 다양한 장르들이 들어가 있는 음악(음원)데이터들을 학습데이터로 사용하여 학습시키면 이 모델은 최소한 음악을 분류할 수 있는 능력이 생깁니다. 이 방식이 비지도학습입니다. 주로 데이터를 분류하는 task 혹은 현업에서는 데이터들의 특징들을 모델로 잡아내기 위한 전처리방식으로 비지도 학습을 사용하곤 합니다.
강화학습(reinforcement learning)
강화학습은 정답도 주지 않고 분류할수 있는 데이터도 주지 않는 학습방법입니다.
??? : 그게 무슨 소리야!!!
바로 행동 심리학에서 기반한 이론을 머신러닝에 적용한 기술로 상(reward)과 벌(punishment)을 주는 방식으로, 모델이 현재상태에서 가장 최고, 최적의 결과(최고의 award를 받는 방향으로)를 산출하도록 학습하는 기법입니다. 만약에 어떤 최적의 길을 찾아내는 task를 지도 학습으로 모델을 설계한다고 가정해봅시다. 지도학습일 경우 각 갈림길 마다 분류를 통해 경로를 결정해야하기 때문에 경로의 길이가 길어질수록 엄청난 양의 학습데이터와 고성능의 컴퓨터가 필요합니다. 이런 task를 강화학습에 적용하게 되면 지도학습의 경우보다 적은 양의 데이터로 최적의 값을 산출이 가능합니다. 알파고가 바로 강화학습을 통해 생성된 기술입니다.
4. What is Deep learning?
앞서 머신러닝이란 ‘다양한 데이터들을 통해 기계가 규칙을 찾도록 학습시키는 기술’이라고 하였습니다. 여기서 나아가 딥러닝이란 모델을 학습시, 인간이 데이터들의 특징을 모델에게 알려주는 것이 아니라 모델로 하여금 데이터들의 특징 추출부터 결과 생성까지 모든 과정을 일임하게 하는것으로 ‘머신러닝이 인간이 학습하는 방식을 모방했다면 인간의 뇌구조와 유사한 방식으로 모델을 학습시키면 어떨까?’라는 개념에서 시작되었습니다.
그래서 뇌에서 생물학적으로 정보를 전달하는 방식인 뉴런에서 그 아이디어를 착안하여 Artificial Nueral Network를 만들어냈습니다. 인간의 뉴런은 신호를 전달할 때, 수많은 뉴런들이 연걸되어 있으며 특정 임계값이 넘어가면 다음 뉴런으로 신호를 전달합니다. 이런 컨셉에 착안하여 수많은 뉴런들이 연걸되있는 구조에서 각 뉴런을 layer로, 그러한 layer(뉴런)를 다중으로 쌓아서 출력을 산출하는 방식으로 모델을 설계하고 학습하는 방식이 deep learning입니다.
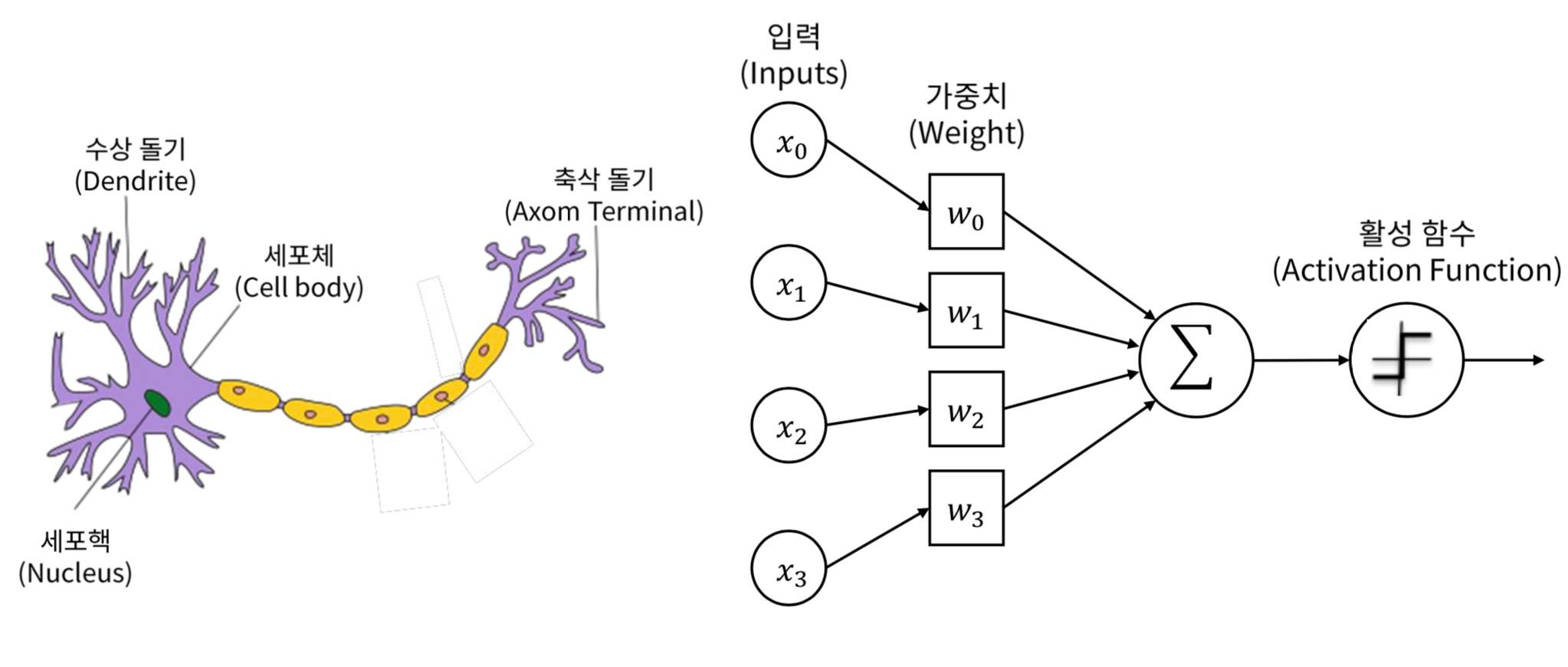
여기서 ‘deep’이 바로 모델을 다중으로 쌓았기에 이를 수직적인 시야로 보면 깊다는 의미이기에 deep learning이라고 한 것입니다. 사실 ‘딥러닝’이라는 컨셉은 57년에 이미 등장한 기술입니다. 그러나 낮은 컴퓨팅 파워로 인해 빛을 보지 못하였다가 2010년 이후, 기술이 발전함에 따라서 다시 부흥하게 된 기술입니다. 또한 앞서 얘기했듯 인터넷이 활성화되면서 다양하고 많은 양의 데이터를 수집이 가능해져 딥러닝 모델의 성능이 증가한 것도 다양한 요인중 하나입니다.
그러면 현재 딥러닝의 큰 분야는 어떤게 있고 상용화되어 많이 사용되는 기술에는 어떤것이 있는지 설명드리겠습니다.
VISION
비전 분야의 경우, 딥러닝이 비전을 통해 시작되었다고해도 과언이 아닐정도로 초창기 딥러닝을 이끌었던 분야입니다.
-
이미지 분류 (image classification)
이미지 분류는 딥러닝 입문자에게 예제로 가장 설명 혹은 과제로 사용되는 기술이며 그만큼 다양한 분야에 사용되고 있습니다. 간단한 이미지분류부터, 신체 인식, CCTV, 제조업, OCR, 의학 등 매우 다양한 분야에 사용되고 있습니다.
basic classification
입력된 사진이 어떤사진인지 분류하는 기본 task

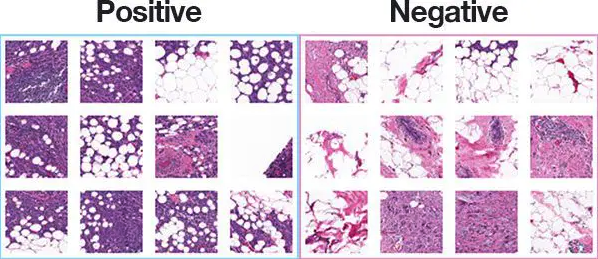
의학
입력된 사진에 암세포 혹은 다른 질병이 있는지 확인하는 task
-
객체 탐지 (Object Detection)
객체 탐지는 해당 이미지에서 객체의 위치를 추적하는 task입니다.

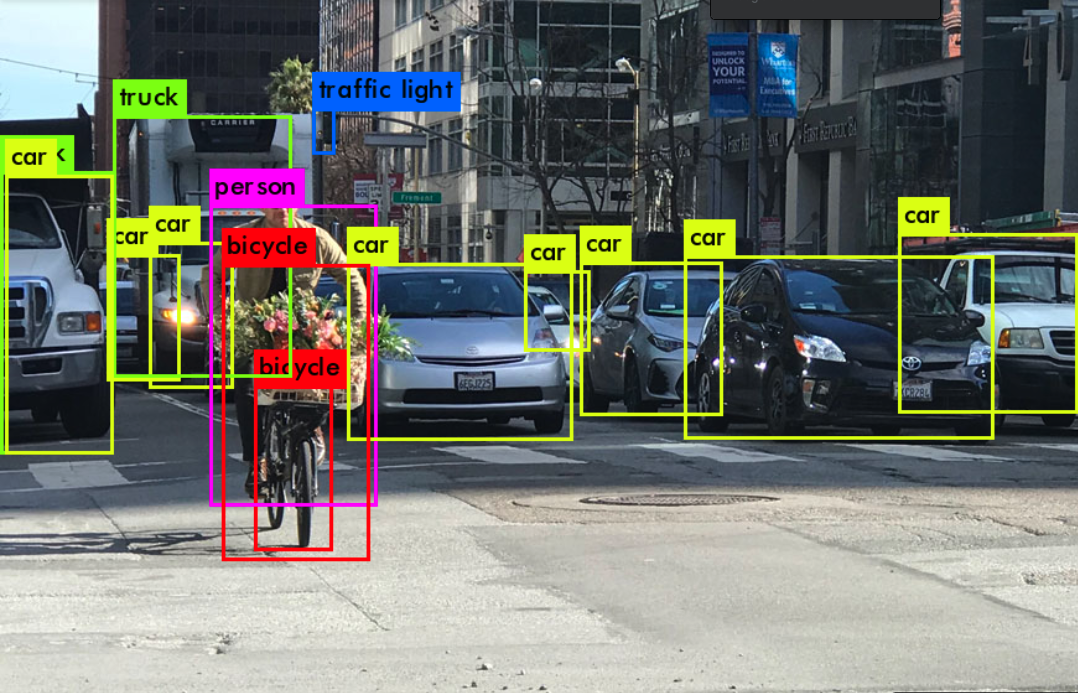
자율주행
입력된 사진에 모든 객체들의 위치를 추적하는 task로 자율주행에서 객체의 위치를 파악하고 차량이 움직여야하기에 핵심적인 기술 중에 하나입니다.
제조업
입력된 사진에 잘못 제작된 부분이 있는지 추적하는 task + 입력된 사진에 잘못 제작된 제품이 있는지 맞추는 task입니다.

CCTV 입력된 사진에 사람들의 위치를 추적하는 task

신체 인식
신체특정 부분을 추적하는 기술로, 예전에 많이 사용했던 snow어플에서 가장 중요한 기술입니다.

OCR
우리가 스마트폰에서 카메라로만 카드인식을 할떄 사용하는 task로, 카드번호의 위치를 추적할 수 있습니다. 이 기술과 이미지 분류의 해당 그림이 무슨 숫자를 의미히는지 구별할 수 있는 task로 카메라에 보이는 숫자를 알 수 있습니다.

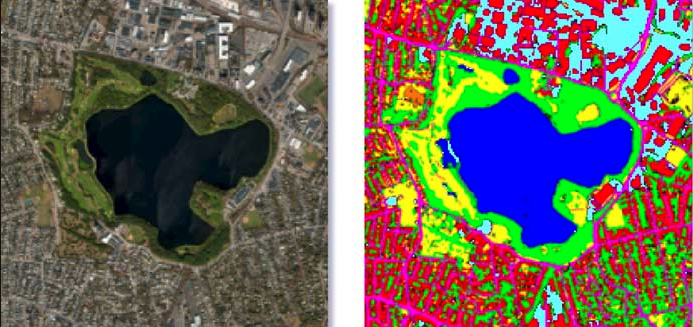
- 객체 분할 (Segmentation)
객체분할은 이미지에서 각 객체들의 위치등을 분리하는 기술입니다. 자율주행 자동차 부터 바이오, 위성 등 많은 분야에 사용되고 있습니다.


자율주행

바이오
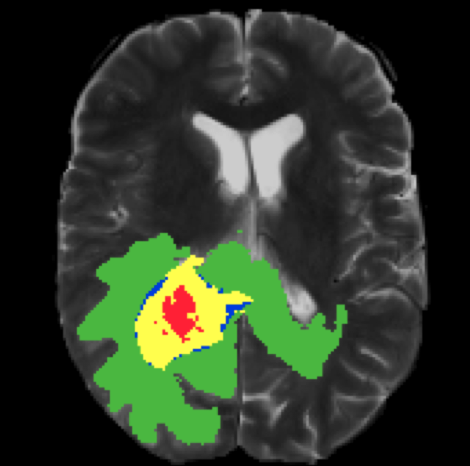
위성
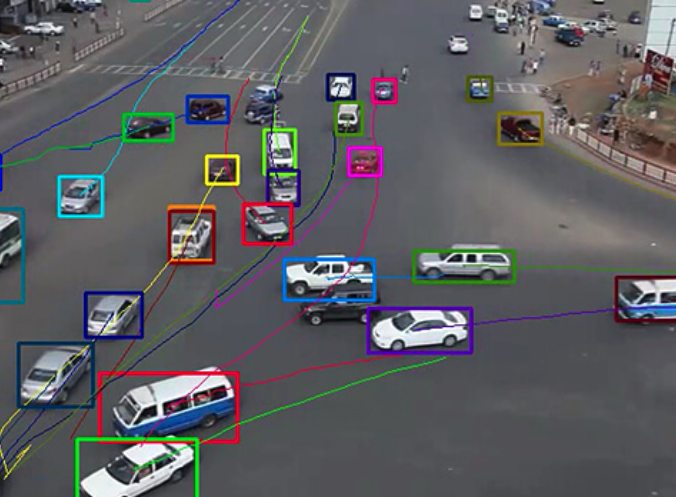
- 객체 추적 (object tracking)
사물의 위치를 추적하는 기술로, 자율주행 자동차의 핵심기술이라고 할 수 있습니다.

SPEECH
- 음성인식 (speech recognition)
음성인식기술은 우리가 말하는 내용을 text로 바꾸거나 컴퓨터가 이해할수 있는 언어로 변환하는 기술입니다. 우리가 스마트폰에서 말하는 모든 내용은 음성인식기술을 이용하여 스마트폰에 전달됩니다. 그래서 보통 STT(speech to text)라고 부르는 모든 기술은 음성인식을 사용한 기술입니다.

- 음성합성 (speech synthesis)
음성합성기술은 우리가 text로 입력한 내용을 실제 목소리로 합성하는 기술입니다. 우리가 스마트폰에 “날씨 알려줘”라고 얘기하면 스마트폰에서 나오는 목소리는 모두 음성합성을 이용하여 스마트폰에서 저장된 text를 음성으로 합성하여 출력되는 결과물입니다. 그래서 보통 TTS(text to speech)라고 부르는 모든 기술은 음성합성을 사용한 기술입니다.
- 음원분리 (source separation)
음원분리는 두개 이상의 음원이 섞였을 경우, 이를 분리해내는 기술로 두명 이상이 동시에 말을할때나 노래에서 악기를 분리하거나, 잡음이 있는 음원에서 목소리만 분리할 때 많이 사용됩니다.
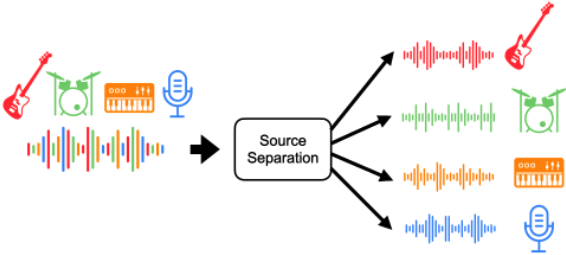
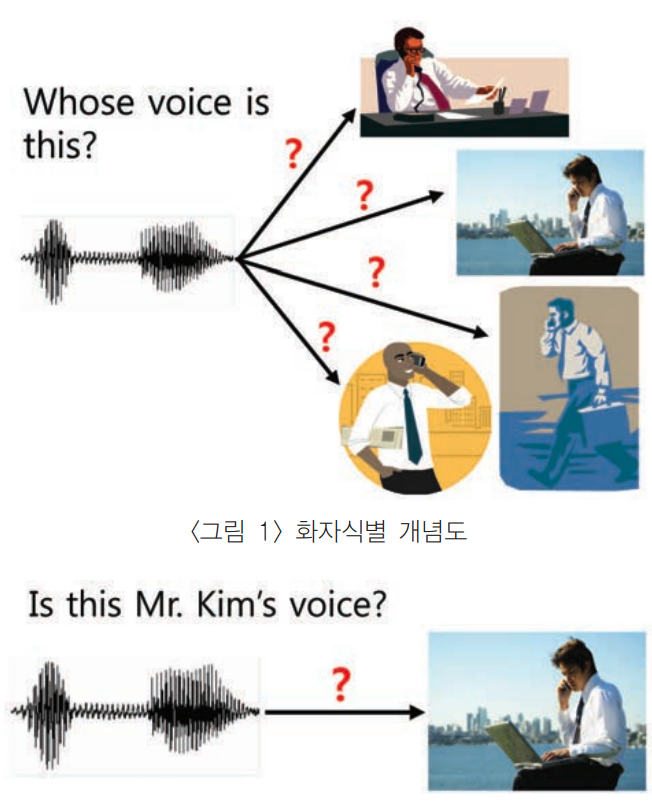
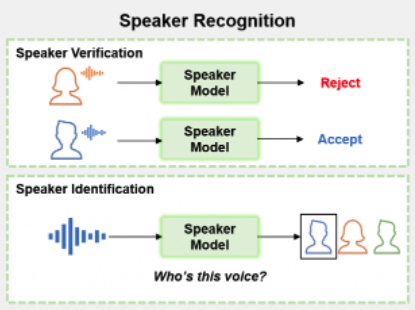
- 화자인식 (speaker recognition)
화자인식은 화자가 누구인지를 맞추는 기술입니다. 이를 이용하여, 특정 목소리에만 반응하게 하는 보안 알고리즘을 개발하거나, 해당 목소리가 누구인지 탐지하는 알고리즘 혹은 딥러닝용 데이터를 라벨링할때등 많은 응용방법이 존재합니다.
NLP
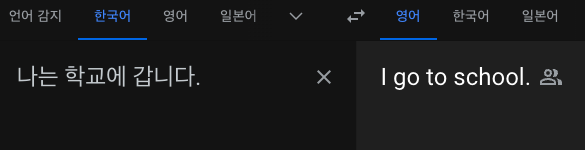
- 번역 (translation)
번역은 말 그래도 언어를 번역해주는 기술로, 많은 사람들이 알고있는 google번역이나 파파고가 이 기술을 이용하여 개발되었습니다.
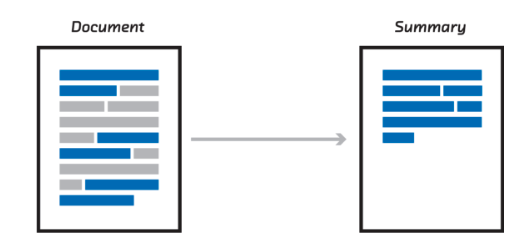
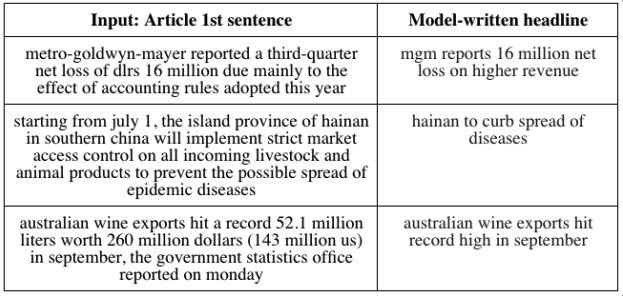
- 텍스트 요약 (text summarization)
텍스트 요약은 문서 혹은 문장을 압축하거나 분석, 요약을 해주는 기술입니다.
- 질의응답 (Question Answering)
질의응답은 데이터에서 질문에 대한 대답을 찾는 기술로 챗봇이 이를 대표하는 기술이라고 할 수 있습니다.

챗봇
- 텍스트 분류 (text classification)
텍스트 분류는 입력된 문장에서 특징에 따라 문장을 분류하는 기술입니다. NLP용 데이터 구축을 하거나 게임 욕설 blur처리 등 다양한 분야에 사용되고 있습니다.
5. 정리
지금까지 AI 머신러닝 딥러닝에 대해 설명해보았습니다. AI와 머신러닝, 딥러닝의 차이점에 대해 알아보았고 AI부터 우리가 많이사용하는 딥러닝까지의 역사와 머신러닝의 종류 그리고 딥러닝 분야와 응용기술에 대해 설명하였습니다. 이를 통해 AI부터 딥러닝까지 전반적인 내용을 설명하였고 이후 진행되는 딥러닝 포스팅을 좀더 의미있게 또 재미있게 읽을 수 있을것이라 생각됩니다.
6. reference
youtube link
- https://www.youtube.com/watch?v=BUTP-YsD3nM
- https://youtu.be/BUTP-YsD3nM
Wiki : https://ko.wikipedia.org/wiki/%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5